Vaihingen Dataset
ISPRS-Vaihingen
The Vaihingen dataset is for urban semantic segmentation used in the 2D Semantic Labeling Contest - Vaihingen.
The dataset can be requested at the challenge homepage. You need to get a package file named Vaihingen.zip (size: 14.9 GB), and unzip this package to get a folder named Vaihingen which contains 14 files as follows:
1 | Vaihingen |
dataset_prepare.html#isprs-vaihingen | mmsegmentation docs
其中我们需要 ISPRS_semantic_labeling_Vaihingen.zip 和 ISPRS_semantic_labeling_Vaihingen_ground_truth_COMPLETE.zip 两个文件
1 | vaihingen |
其中 ISPRS_semantic_labeling_Vaihingen.zip 包含原始的 IRRG 图像
1 | ISPRS_semeantic_labeling_Vaihingen.zip |
对于标签一共有两种,一种是不带 eroded 黑色边界的 ground truth,另一种是带这种 eroded 黑色边界的 ground truth。请选择使用,本文这里选择的是不带黑色边界的 ground truth,即 ISPRS_semantic_labeling_Vaihingen_ground_truth_COMPLETE.zip 这个文件。
数据集中的图片为 tif 格式,Windows 自带的各种图片工具可能不能正常打开,使用 vscode 中 tif 插件,例如 TIFF Preview,可以查看 数据集的 tif 原图。
Correspondence between colors and categories
1 | ''' |
注意如果使用的是 ISPRS_semeantic_labeling_Vaihingen_ground_truth_eroded_COMPLETE.zip 作为标签,其包含了边界标注,对应的 color_map 会有所不同
1 | ''' |
Configuration
Use the code below to convert the original images to patches (pixels 512×512)
In the 2_Ortho_RGB.zip file, it contains 33 pictures with different sizes:
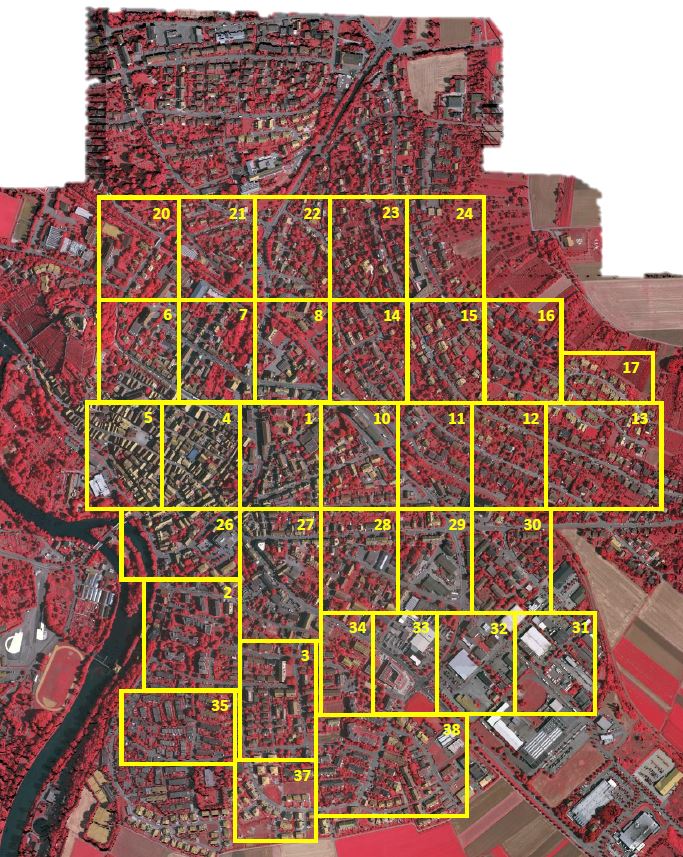
In the default configuration, We assign the training, validation, and test sets as follows, 15 for training, 1 for validation and 17 for testing
1 | splits = { |
文件结构
1 | $ tree datasets -L 3 |
1 | $ ls -l path/to/vaihingen_512x512/img_dir/train/ | grep "^-" | wc -l |
Split Code
Prepare Dataset: ISPRS-Vaihingen | mmsegmentation doc
tools/dataset_converters/vaihingen.py | mmsegmentation github
注意我们在下面代码中使用的是 cv2 来读取和保存 crop 后的标签图片,所以使用的 color map 是 BGR 格式的。cv2.imread 在读取本地的 RGB 图片时会按照 BGR 的顺序读取,所以 cv2.imread 读取在内存里面图片的通道顺序是 BGR 的;cv2.imwrite 在保存图片时默认内存里面需要被保存图片的通道顺序是 BGR 的,它会按照 BGR 的通道顺序将图片写到本地变成 RGB 的通道顺序。
1 | ''' |
1 | # ref: https://github.com/open-mmlab/mmsegmentation/blob/main/tools/dataset_converters/vaihingen.py |
mmsegmentation potsdam.py 代码中的 color_map
源代码见链接 potsdam.py | github,下面的代码块是截取的 color_map 部分
mmsegmentation 源码中对 color_map 的设置为 BGR,与正常的 RGB 正好相反,这一点需要注意。
1 | # mmsegmentation 的 color_map 颜色顺序为 BGR |
mmsegmentation 之所以标注 BGR 的颜色顺序,应该是其 imread 和 imwrite 方法的底层调用了 cv2 的 imread 和 imwrite,或者模仿了它们的设计。这里可以参考一下这篇博客 cv2如何处理RGB和BGR | 文羊羽。
-
mmsegmentaion 的 color map, BGR
1
2
3
4
5
6
70: [ 0 0 0] : boundary
1: [255 255 255] : impervious surfaces
2: [255 0 0] : background
3: [255 255 0] : car
4: [ 0 255 0] : tree
5: [ 0 255 255] : low vegetation
6: [ 0 0 255] : building -
正常的 color map, RGB
1
2
3
4
5
6
70: [ 0 0 0] : boundary
1: [255 255 255] : impervious surfaces
2: [ 0 0 255] : building
3: [ 0 255 255] : low vegetation
4: [ 0 255 0] : tree
5: [255 255 0] : car
6: [255 0 0] : clutter/background
ann2rgb
1 | from typing import Union |